Quick Navigation
- Introduction
- Editor’s Choice
- Historical Facts
- General Web Search Engine Statistics and Facts
- Web Search Engine Market Share
- The US Web Search Engine Market Share
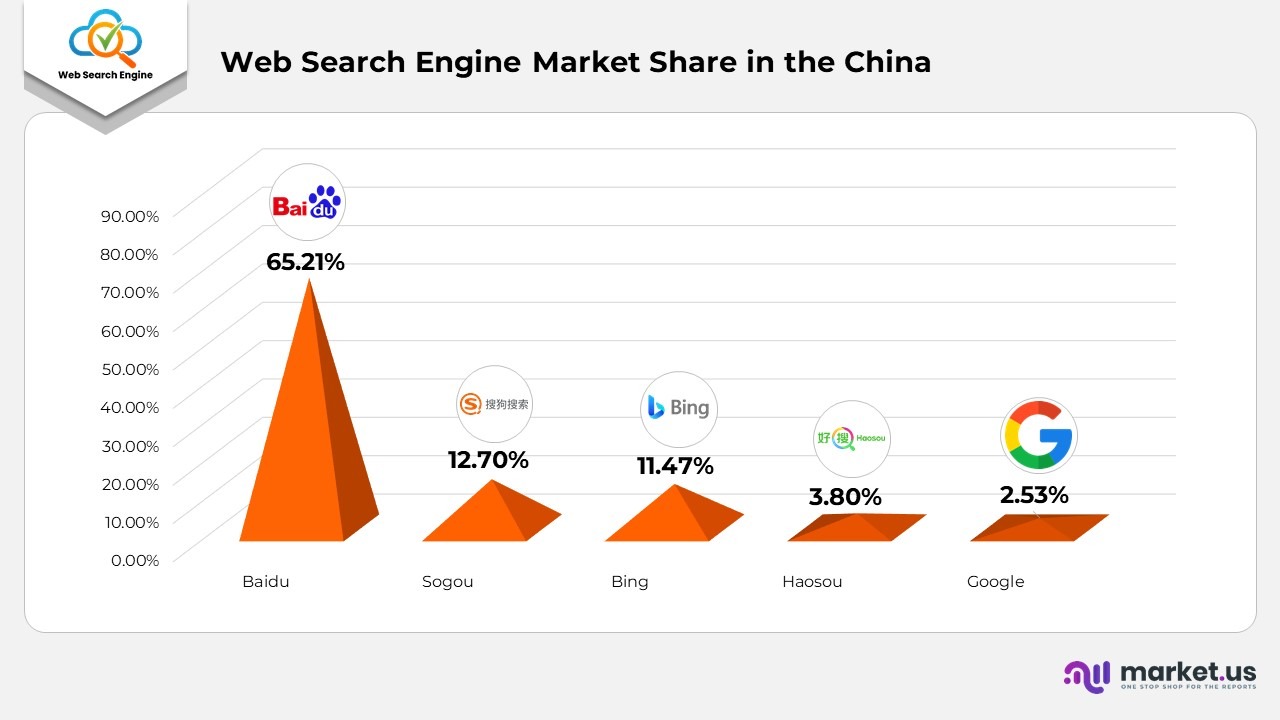
- Web Search Engine Market Share in China
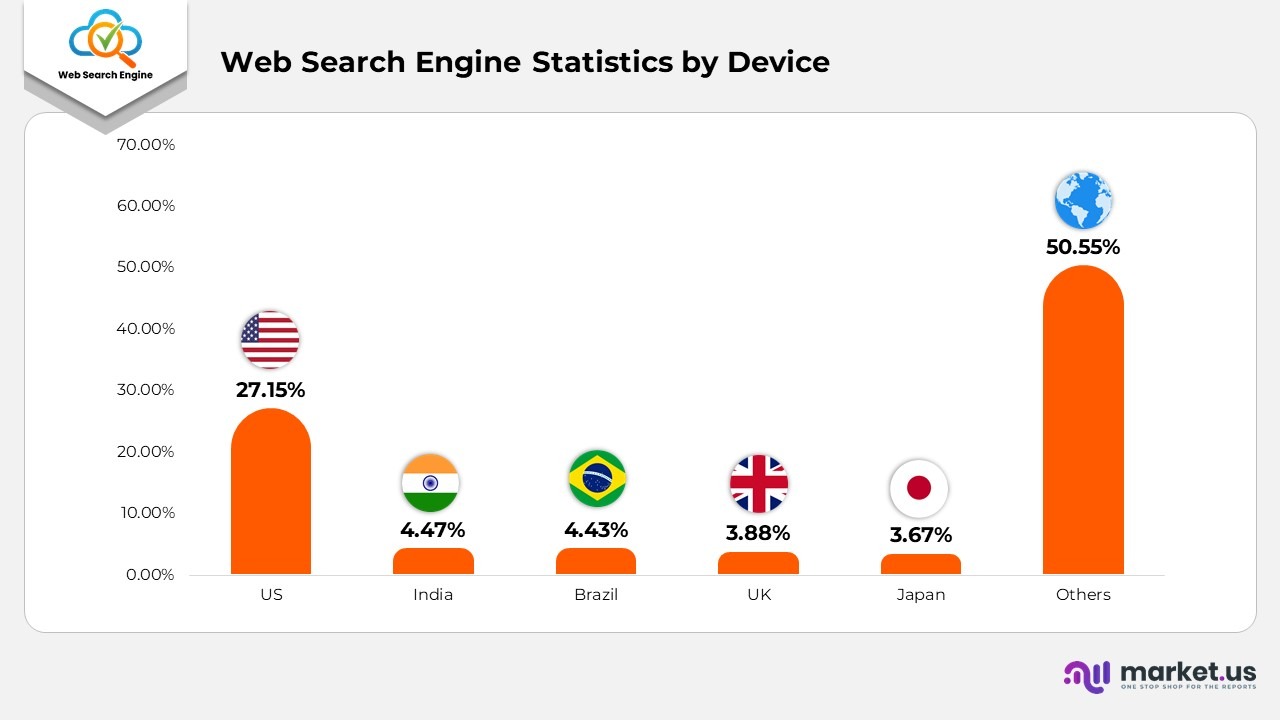
- Web Search Engine Statistics by Device
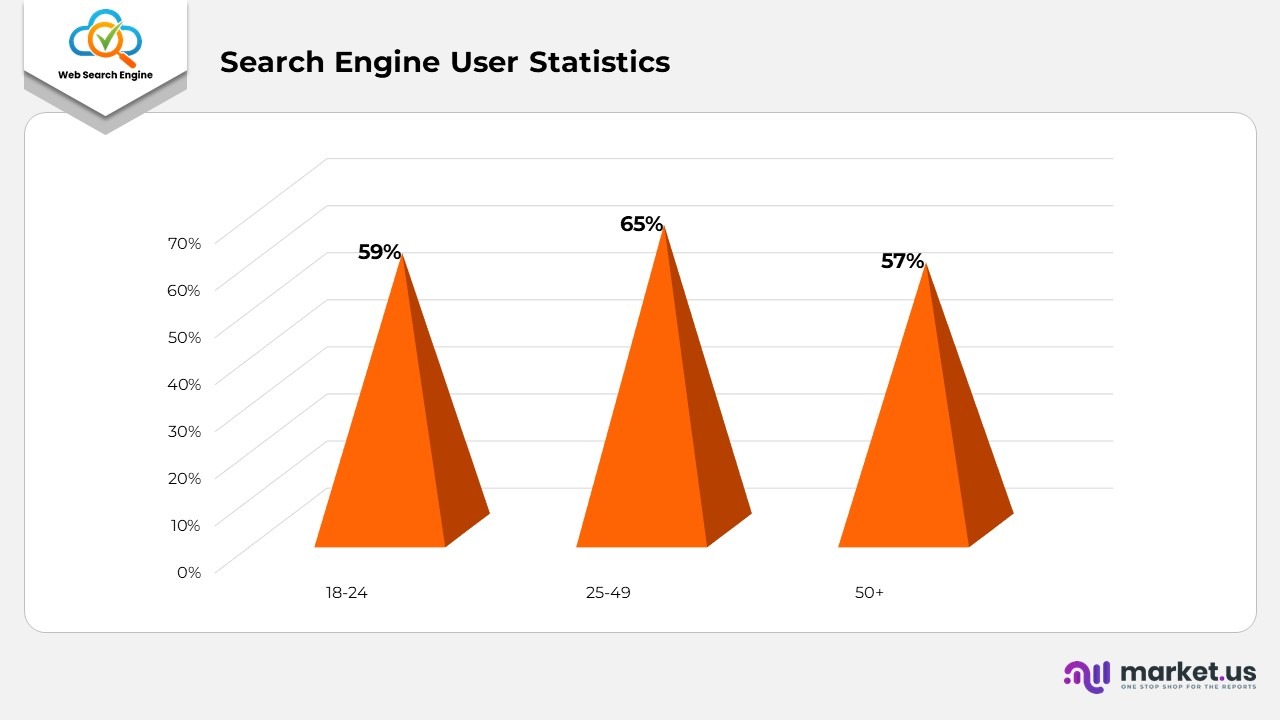
- Search Engine User Statistics
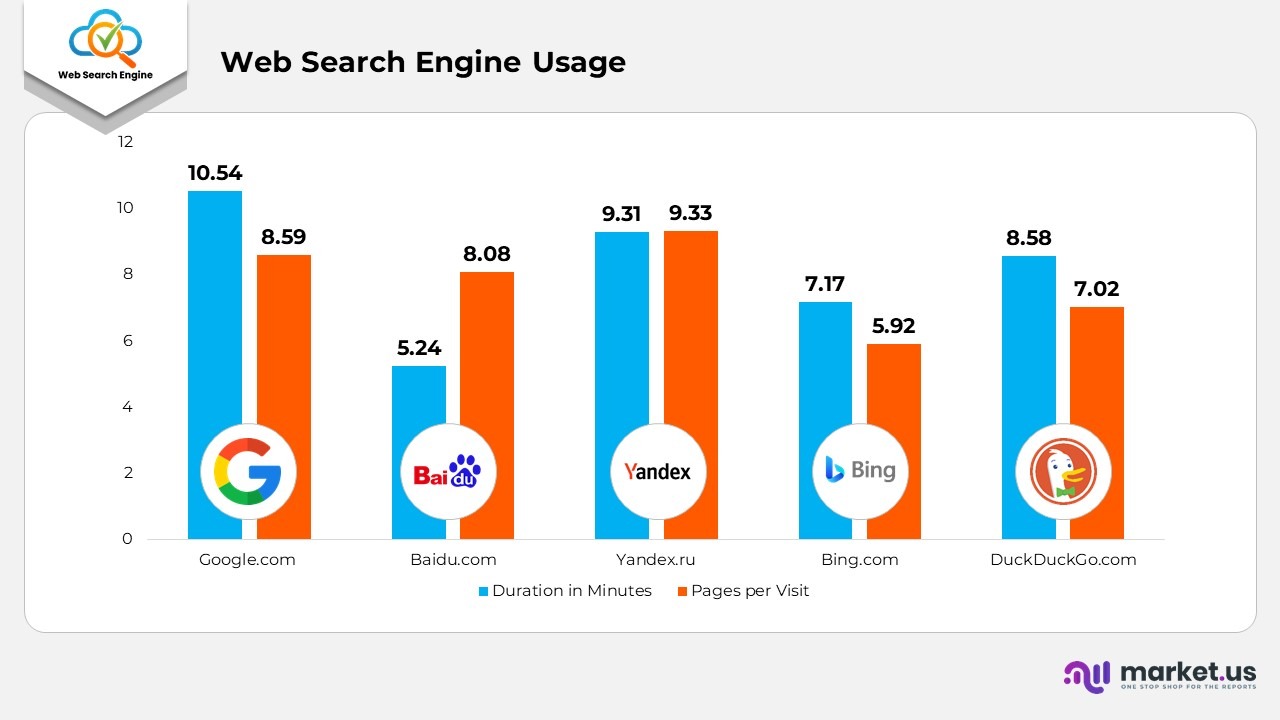
- Web Search Engine Usage
- Web Search Engine Marketing Statistics
- Google Search Engine Statistics
- Bing Search Engine Statistics
- Yahoo! Search Engine Statistics
- Baidu Search Engine Statistics
- Web Search Engine Fun Facts
- Recent Developments
- Web Search Engine Future Predictions
- Conclusion
Introduction
Web Search Engine Statistics: A web search engine is a software application designed to assist users in locating information on the internet through the use of keywords. It operates by employing automated programs known as crawlers to explore the web, thereby generating an index of the discovered content. When a user submits a query, the search engine utilizes algorithms to search its index and deliver a ranked list of pertinent web pages, images, and other results.
Web search engines, such as Google, play a vital role in online information retrieval, with Google handling over 8.5 billion queries each day and maintaining a significant market share. Notable statistics indicate that search engines account for 68% of all website traffic, 93% of online interactions commence with a search, and users generally focus on the first page of results. Google’s supremacy is particularly pronounced in mobile search, where it commands over 93% of the market share.
Web search engines have revolutionized the way individuals access information online, progressing from basic keyword-matching tools to advanced artificial intelligence systems. Gaining insight into web search engine statistics and user behavior trends is crucial for informing digital marketing strategies and SEO methodologies.
Editor’s Choice
- With a 91.62% market share, Google stands as the leading search engine.
- As of January 2023, Google holds the largest global market share in search engines at 93.74%.
- In the fourth quarter of 2021, tablets and smartphones represented 63% of organic search engine traffic in the United States.
- As of August 2022, 27% of the global online population utilized voice search.
- As of April 2021, over 76% of consumers utilized search engines to locate the physical addresses of various places and businesses.
- In AdWords, the average click-through rate for search across all industries is 3.17%.
Historical Facts
- The earliest internet search engines were in existence before the Web’s launch in December 1990, with the WHOIS user search dating back to 1982.
- The first well-documented search engine capable of searching content files, particularly FTP files, was Archie, which was launched on September 10, 1990.
- The introduction of Gopher, generated in 1991 by Mark McCahill at the University of Minnesota, led to the development of two additional search programs, Jughead and Veronica.
- In June 1993, Matthew Gray, then associated with MIT, developed what is considered the first web robot, the Perl-based World Wide Web Wanderer, which he used to create an index referred to as “Wandex”.
- The second search engine available on the web, Aliweb, was introduced in November 1993.
- The first search engine that gained widespread usage on the Web was Yahoo! Search.
- Microsoft’s newly branded search engine, Bing, was introduced on June 1, 2009.
- As of 2019, the active search engine crawlers include those from Bing, Baidu, Google, Brave, DuckDuckGo, Sogou, Mojeek, Gigablast, and Yandex.
General Web Search Engine Statistics and Facts
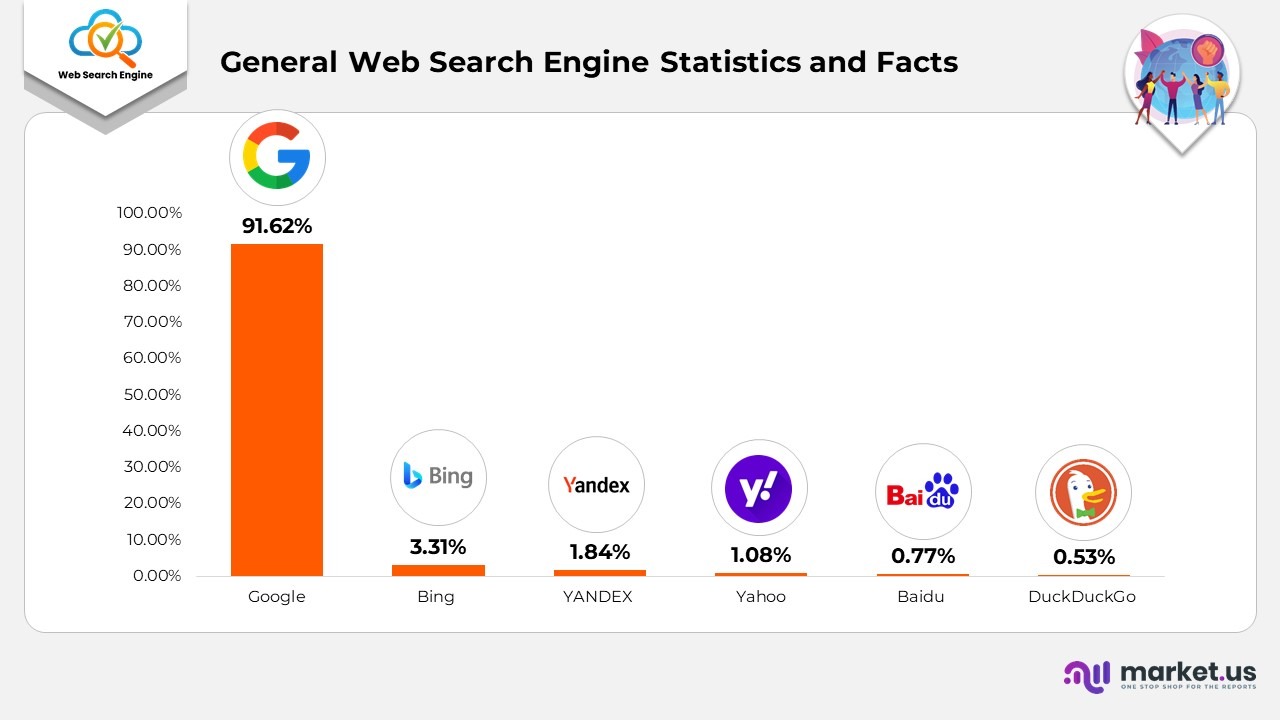
- With a 91.62% market share, Google stands as the leading search engine.
- Google represents 78% of desktop search traffic and 89% of mobile search traffic.
- Baidu holds over 76% of the search engine market in China.
- Google handles approximately 63,000 search inquiries every second.
- In 2020, Russia submitted more content deletion requests than any other nation.
- About 93% of all web traffic is generated through a search engine.
- The average click-through rate (CTR) for the top position on a Google search result is 19.3%.
- 46% of all searches conducted on Google are related to local content.
- 98% of internet users engage with a traditional search engine at least once a month.
- As of February 2023, Google was the most utilized mobile search engine, accounting for 93.74% of usage.
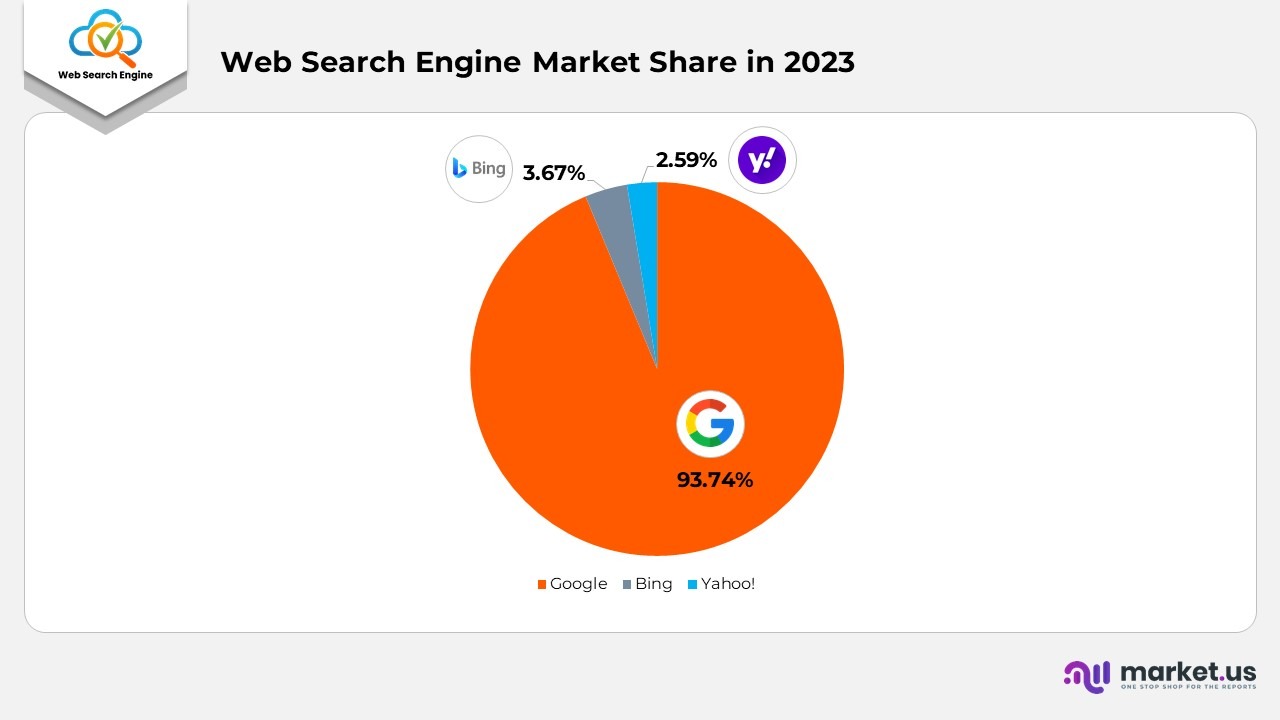
- As of January 2023, Google holds the largest global market share in search engines at 93.74%.
- Bing follows in second place with 3.67%, while Yahoo! ranks third with 2.59%.
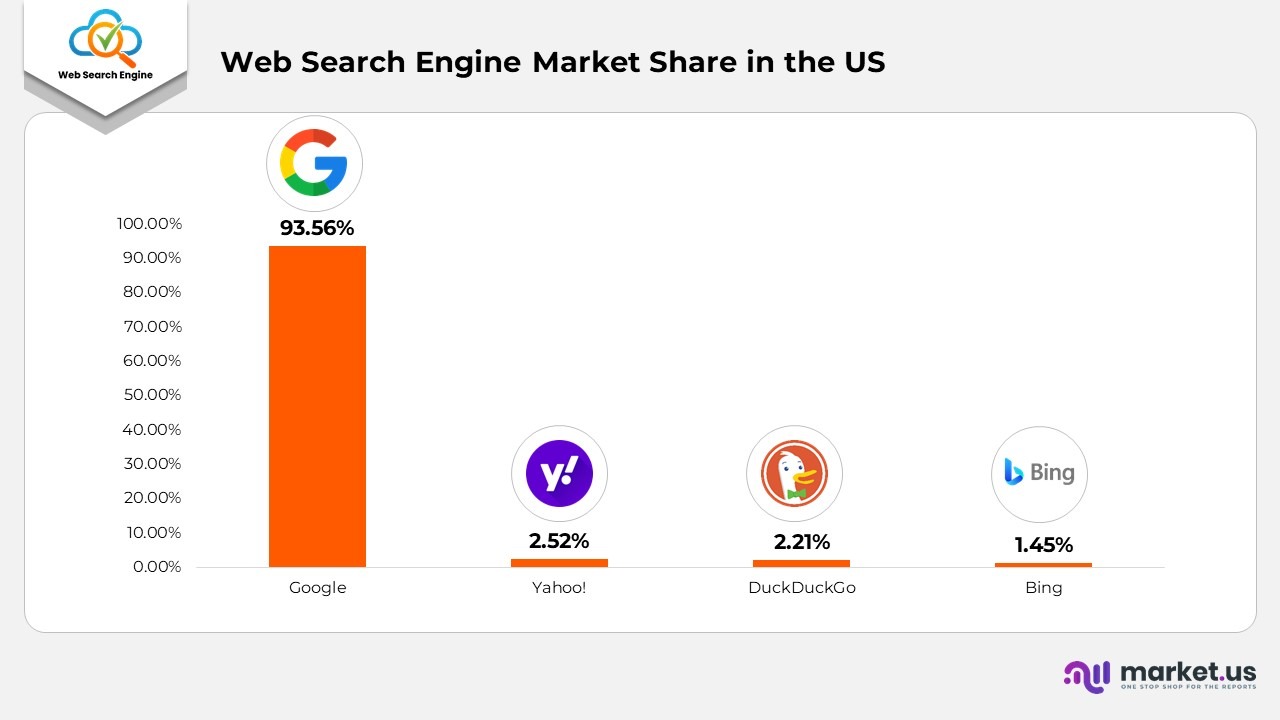
- In 2022, Google achieved a remarkable 93.56% share of the mobile search market in the United States.
- In the US, Yahoo! secured the second position with a 2.52% market share, trailed by DuckDuckGo at 2.21%.
- As of January 2023, Baidu dominates China’s search engine market with a share of 65.21%.
- In the UK, Google represented 86.31% of the market share in September 2021.
- Bing was the second largest with 9.62%, followed by Yahoo! at 2.36%.
- Google 93.56%
- Yahoo! 2.52%
- DuckDuckGo 2.21%
- Bing 1.45%
- Baidu 65.21%
- Sogou 12.7%
- Bing 11.47%
- Haosou 3.8%
- Google 2.53%
Web Search Engine Statistics by Device
- In the fourth quarter of 2021, tablets and smartphones represented 63% of organic search engine traffic in the United States.
- During the first quarter of 2021, these devices accounted for 59% of organic search engine visits, which rose to 61% in the second quarter and reached 64% in the third quarter.
- As of February 2023, the United States generated the highest volume of desktop traffic to Google.
- In 2022, mobile devices contributed 59.54% of traffic in the third quarter, 58.99% in the second quarter, and 55.79% in the first quarter.
- In contrast, in 2021, they produced 54.8% in the first quarter, 55.09% in the second quarter, 55.78% in the third quarter, and 54.4% in the fourth quarter.
- As of February 2023, Google was the leading mobile search engine, with a usage rate of 93.74%.
- Mobile devices, excluding tablets, made up 59.16% of global search engine traffic in the fourth quarter of 2022.
Search Engine User Statistics
- As of August 2022, 27% of the global online population utilized voice search.
- Among those who favored voice search, 59% were between the ages of 18 and 24, 65% were aged 25 to 49, and 57% were over the age of 50.
- Approximately 85% of Americans engaged with search engines on a daily basis as of February 2021.
- In Japan, Google held the title of the most widely used search engine as of March 2022.
Web Search Engine Usage
- As of February 2023, Google.com held the title of the most visited website within the search engines category.
- Users dedicated an average of 10.54 minutes on Google.com, navigating approximately 8.49 pages during each visit. In contrast, Baidu.com ranked second, with users spending an average of 5.24 minutes and viewing around 8.08 pages per visit.
- As of April 2021, over 76% of consumers utilized search engines to locate the physical addresses of various places and businesses.
- In January 2022, Google accounted for more than 50% of all search engine queries in the United States.
Web Search Engine Marketing Statistics
- The click-through rate for the second position is around 10.57%, which is nearly half of that for the first position. In contrast, 75% of all searchers do not proceed beyond the first page of their search results.
- Statistics pertaining to search engine optimization indicate that images constitute only 12% of the impressions in these results, whereas videos account for a mere 3.05%. The click rate for images is also notably low, representing just 0.62% of all clicks.
- 38% of marketers consider Google’s zero-click pages to be the most significant threat to SEO.
- In AdWords, the average click-through rate for search across all industries is 3.17%.
- The average cost per click in AdWords for search across all industries is $2.69.
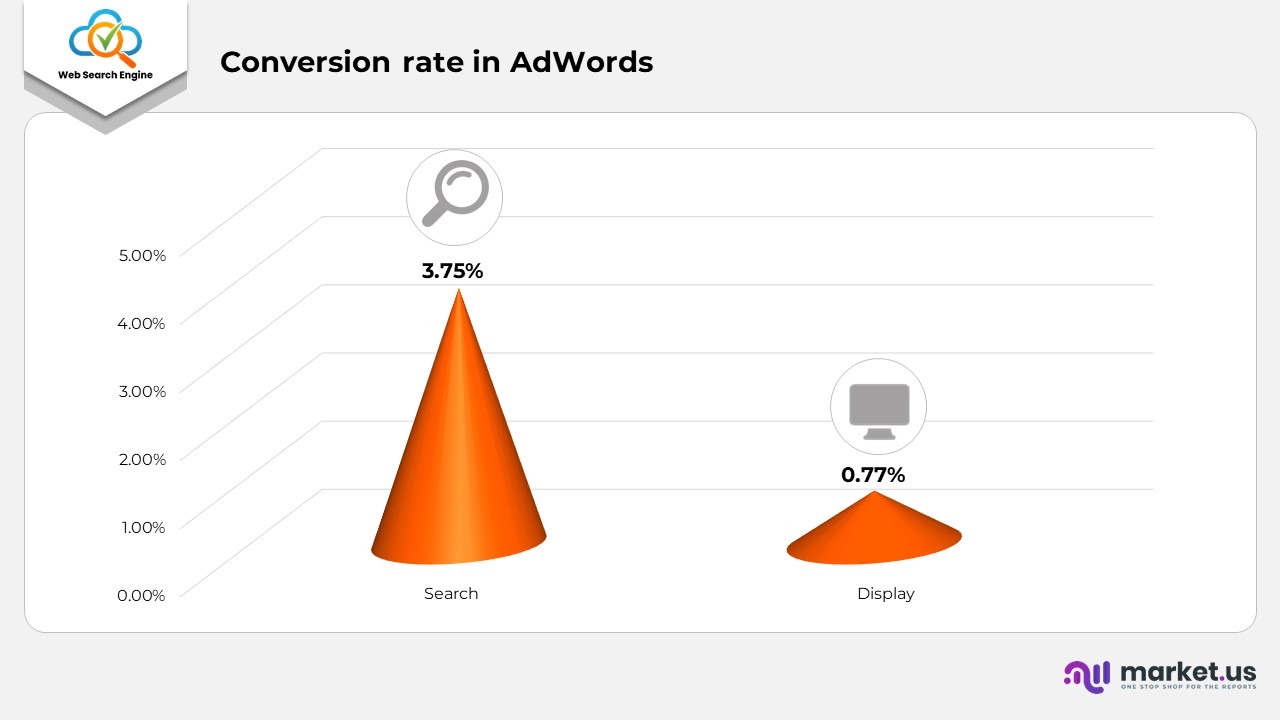
- The typical conversion rate in AdWords stands at 3.75% for search and 0.77% for display across various industries.
- Organizations that integrate organic SEO with PPC advertising experience 25% more clicks and 27% greater profits in comparison to utilizing just one approach.
- Incorporating a video on your website’s landing page enhances your likelihood of ranking on Google’s first page by over 50%.
Google Search Engine Statistics
- As of February 2022, 15% of daily search inquiries on the Google search engine were new search queries.
- In 2022, Google handled approximately 99,000 search inquiries every second.
- The term “Google” was the most frequently searched keyword on Google globally in 2022.
- Voice search on Google accounted for 20% of all searches conducted on the platform.
Bing Search Engine Statistics
- Bing ranks as the second-largest search engine, holding a global market share of 2.82% as of February 2023.
- Bing was accessible in approximately 105 different languages as of March 2023.
- By May 2022, Bing recorded nearly 1.2 billion visits globally.
- As of January 2021, Facebook was the most frequently searched term on Bing in the United States.
Yahoo! Search Engine Statistics
- In February 2023, Yahoo! garnered approximately 2.83 billion visits worldwide.
- Over 50% of Yahoo!’s traffic in February 2023 originated from the United States.
- As of March 2023, Yahoo! has a higher number of male users compared to female users.
Baidu Search Engine Statistics
- In 2022, Baidu achieved an annual revenue exceeding $17.9 billion.
- As of February 2023, Baidu stood as the leading search engine in China.
- In February 2023, Baidu attracted 285.2 million visits.
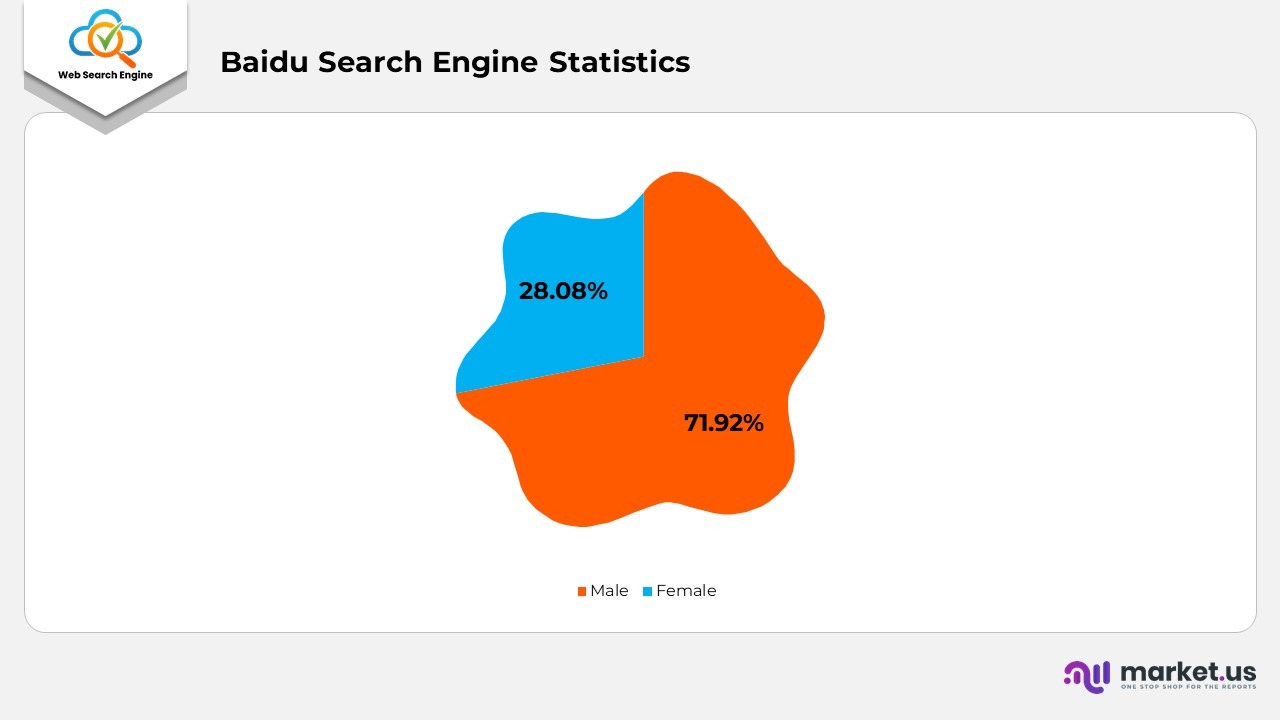
- As of March 2023, the number of male users on Baidu was three times greater than that of female users, with males constituting 71.92% and females 28.08% of the total user base.
Web Search Engine Fun Facts
- The first web search engine World Wide Web Worm, developed in 1993/94 at University of Colorado, indexed around 110,000 web pages.
- The original name of Google was ‘Backrub’.
- Google reportedly recorded more than 3.5 billion searches per day.
- Search engines themselves now use algorithms to pull “fun facts” about people, animals, etc. to improve engagement.
Recent Developments
- Recent advancements in web search engines are centered around the incorporation of generative AI, resulting in conversational and multimodal search experiences. Leading companies such as Google and Bing are utilizing AI to deliver more straightforward, summarized responses and to manage intricate queries, while also improving privacy measures and increasing the prevalence of multimodal searches (text, image, voice).
- Google’s dominance persists with approximately 90.4% of the global desktop market share as of September 2025, while the integration of AI is on the rise, with AI tools representing 0.55% of all desktop events in March 2025, a significant increase from 0.17% the previous year. In the meantime, Google implemented over 4,700 algorithm modifications in 2022, averaging 13 changes per day, and its search advertising revenue soared to a record $234 billion in 2024.
Web Search Engine Future Predictions
- By 2026, traditional search engine traffic could fall by 25% as users turn to AI assistants.
- By 2026, many queries on search engines will be handled by AI assistants, and fewer will result in a webpage click.
Conclusion
Web search engines have transformed from basic keyword-driven systems into sophisticated platforms that utilize artificial intelligence to deliver personalized results. Notable points include Google’s leading position in the search market, the progression of SEO from mere keyword stuffing to a focus on user experience, and the considerable influence of mobile optimization and content quality on search rankings. The functionalities of search engines are continually advancing, incorporating more innovative features such as voice search and video, thereby establishing them as crucial access points to the extensive information available on the internet.