
Quick Navigation
- Report Overview
- Key Takeaways
- Analysts’ Viewpoint
- US Synthetic Data Generation Market
- Data Type Analysis
- Offering Analysis
- Generation Technique Analysis
- Application Analysis
- End Use Analysis
- Report Segmentation
- Driver
- Restraint
- Opportunity
- Challenge
- Growth Factors
- Emerging Trends
- Business Benefits
- Key Regions and Countries
- Key Player Analysis
- Recent Developments
- Report Scope
Report Overview
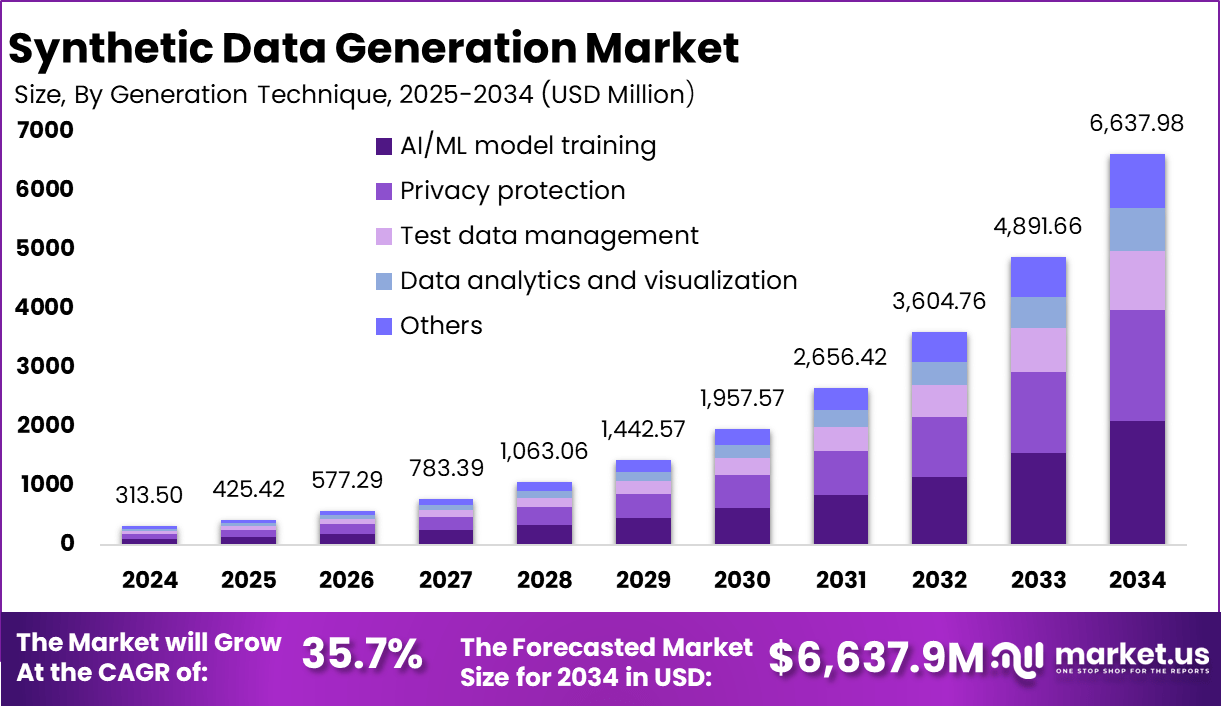
The Synthetic Data Generation Market size is expected to be worth around USD 6,637.98 Million By 2034, from USD 313.50 Million in 2024, growing at a CAGR of 35.7% during the forecast period from 2025 to 2034. In 2024, North America held a dominant market position, capturing more than a 35% share, holding USD 109.7 Million revenue.
Synthetic data generation is the process of creating artificial datasets that simulate the statistical characteristics of real-world data. This is achieved through advanced computational algorithms that ensure these datasets maintain essential statistical properties while also providing privacy by not containing sensitive personal information.
The generation of synthetic data involves a variety of techniques, including drawing from statistical distributions and agent-based modeling, to produce data that is both diverse and representative of real scenarios. The market for synthetic data generation is rapidly expanding, driven by increasing demand across various sectors such as healthcare, finance, and automotive for data that can be used in machine learning training and testing without privacy concerns.
The market is characterized by a plethora of tools and platforms like Syntho, YData, and Hazy, each offering unique capabilities to enhance data privacy, improve model training, and support regulatory compliance. The synthetic data generation market is expected to grow significantly, offering substantial investment opportunities as more industries recognize the utility and efficiency of employing synthetic datasets.
The demand for synthetic data is largely fueled by its ability to provide high-quality, diverse datasets that are essential for training and testing AI models. Industries such as automotive for self-driving car development, healthcare for patient data simulation, and finance for risk assessment models particularly benefit from synthetic data solutions.
Businesses leverage synthetic data to enhance privacy, increase the diversity of data, and reduce costs associated with data management. Synthetic data also helps in addressing data imbalance, improving the quality of machine learning models, and facilitating data sharing and collaboration across borders without compromising privacy or security.
Key Takeaways
- The Synthetic Data Generation Market is projected to witness substantial growth, reaching approximately USD 6,637.98 million by 2034, up from USD 313.50 million in 2024, expanding at a CAGR of 35.7% during the forecast period from 2025 to 2034.
- In 2024, North America dominated the market, holding more than a 35% share, with a total revenue of approximately USD 109.7 million.
- The U.S. Synthetic Data Generation Market was valued at USD 112.9 million in 2024 and is projected to grow significantly, reaching approximately USD 2,498.3 million by 2034, registering a CAGR of 36.3% over the forecast period.
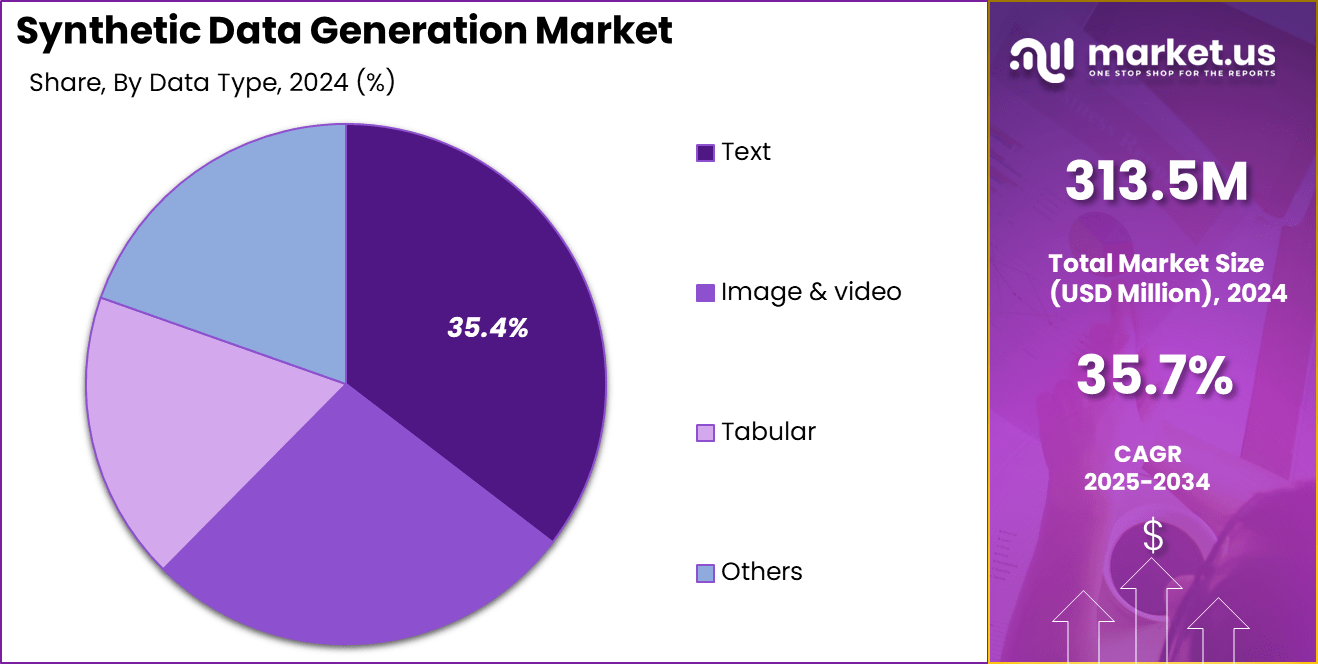
- In 2024, the Text segment emerged as the leading category in the synthetic data generation market, accounting for over 35.4% of the total market share, driven by its increasing adoption in AI model training and NLP applications.
- The Fully Synthetic segment held a dominant position in 2024, contributing more than 39% of the total market share, as organizations prioritized privacy-preserving data generation techniques.
- The Agent-based system segment accounted for the largest share in 2024, capturing over 61.7% of the market, fueled by its ability to create dynamic, behavior-driven synthetic datasets.
- The AI/ML Model Training segment was the leading application in 2024, holding more than 31.7% of the market share, reflecting the growing demand for high-quality synthetic data to enhance machine learning models.
- The Healthcare & Life Sciences sector emerged as the top industry for synthetic data generation adoption in 2024, securing over 23.9% of the market share, as organizations leveraged synthetic data to improve medical research and patient privacy.
Analysts’ Viewpoint
Investment opportunities in synthetic data generation are growing, particularly in developing technology that can create more accurate and diverse datasets, tools for specific industry applications, and solutions that align with global data protection regulations. As the technology matures, there will be increasing opportunities for investing in startups and established companies that are leading the way in synthetic data innovation.
Key factors impacting the synthetic data generation market include technological advancements, regulatory environments, and the increasing complexity of data used in AI applications. Additionally, the need for cost reduction and efficiency in data generation processes plays a significant role in shaping market dynamics.
Technological advancements in synthetic data generation focus on improving the algorithms for generating data that closely mimics real-world distributions and relationships. Innovations in areas like differential privacy, machine learning integration, and automated data profiling are crucial in enhancing the quality and usability of synthetic datasets.
The regulatory landscape significantly influences the synthetic data generation market. As governments worldwide tighten data privacy and security laws, the demand for synthetic data solutions that comply with these regulations increases. These solutions must ensure data privacy without sacrificing the utility for analytical and predictive modeling purposes.
US Synthetic Data Generation Market
The U.S. synthetic data generation market is estimated to be worth USD 112.9 million in 2024, with expectations to experience robust growth, reaching approximately USD 2,498.3 million by 2034. This represents a CAGR of 36.3% from 2025 to 2034.
This rapid growth trajectory highlights the increasing reliance on synthetic data across various sectors, particularly in applications where real data may be limited, sensitive, or biased. The U.S. boasts a robust technological infrastructure, which includes widespread adoption of advanced technologies such as artificial intelligence and machine learning across various industries.
There is a vibrant ecosystem of startups and entrepreneurs in the U.S. focusing on innovative data solutions, including synthetic data generation. This not only drives competition and innovation but also leads to the rapid development of new technologies and applications in the field.
The U.S. market benefits from significant investment in research and development from both public and private sectors. The availability of funding supports continuous innovation and the scaling of new technologies in synthetic data generation.

In 2024, North America held a dominant market position in the synthetic data generation sector, capturing more than a 35% share with revenue amounting to USD 109.7 million. This leadership can be attributed to several foundational factors that uniquely position North America at the forefront of this technology-driven market.
Firstly, North America benefits from a mature technological landscape and strong government support for data-driven initiatives. The presence of major technology firms and startups focused on advanced analytics and artificial intelligence fuels innovation and adoption of synthetic data solutions across various industries.
Furthermore, the regulatory environment in North America, particularly in the U.S., actively promotes the use of synthetic data as a means to comply with strict data protection laws such as HIPAA and CCPA. Companies are increasingly turning to synthetic data to navigate the complexities of data privacy regulations while still gaining valuable insights from their analyses.

Data Type Analysis
In 2024, the Text segment held a dominant market position in the synthetic data generation market, capturing more than a 35.4% share. This notable prominence can be attributed to the escalating demand for natural language processing (NLP) applications across various industries including finance, healthcare, and customer service.
The surge in NLP applications is driven by their capacity to automate and enhance text-based communication, sentiment analysis, and customer interaction, which requires substantial volumes of diverse, high-quality textual data for training and refinement purposes.
Moreover, the proliferation of AI-driven analytics and the increasing adoption of chatbots and virtual assistants have further propelled the demand for synthetic text data. Companies are increasingly relying on synthetic data to train their algorithms, ensuring privacy compliance and reducing the reliance on sensitive or proprietary real-world datasets.
The ability of synthetic data to closely mimic genuine text while eliminating privacy concerns makes it particularly valuable for sectors handling sensitive information, such as banking and healthcare. Additionally, advancements in machine learning techniques have made the generation of realistic and contextually accurate text data more efficient, thereby supporting the expansion of the text data segment.
Tools capable of generating syntactically and semantically correct datasets are critical in training AI models to understand and generate human-like responses, pushing the boundaries of what automated systems can achieve in terms of interaction and functionality.
The ongoing innovation in AI and machine learning algorithms, combined with stringent data protection laws, is expected to continue driving the growth of the Text segment within the synthetic data generation market. This growth is bolstered by the increasing necessity for extensive datasets that are both diverse and deep enough to train sophisticated models, ensuring that the Text segment remains at the forefront of synthetic data applications.
Offering Analysis
In 2024, the Fully synthetic segment held a dominant market position in the synthetic data generation market, capturing more than a 39% share. This segment’s leadership is primarily driven by its ability to provide completely artificial yet highly realistic datasets that are unlinked from real-world data, thereby offering enhanced privacy and security.
This characteristic is particularly vital in industries such as healthcare and finance, where data sensitivity is paramount, and the risk of data breaches must be minimized. Fully synthetic data eliminates the risk of re-identification associated with real data sets, thus adhering to stringent data protection regulations like GDPR in Europe and CCPA in California.
As organizations increasingly prioritize compliance with privacy laws and ethical guidelines, the demand for fully synthetic data solutions has seen significant growth. This type of data is generated from scratch using algorithms and statistical methods, ensuring that the output is free of any biases present in the original data, which can often skew AI model training and lead to flawed predictions.
The versatility of fully synthetic data also plays a crucial role in its popularity. It can be tailored to specific scenarios or requirements, which is not always feasible with partially synthetic or real datasets. For example, in autonomous vehicle development, fully synthetic data can simulate rare or dangerous driving conditions without the need for costly and potentially hazardous real-world tests.
Furthermore, the ongoing advancements in generative models, such as Generative Adversarial Networks (GANs), have improved the quality and efficiency of fully synthetic data generation, making it even more appealing to industries experimenting with cutting-edge AI applications.
These improvements are expected to sustain the dominance of the fully synthetic segment in the synthetic data generation market, as they enable more accurate and diverse datasets that are crucial for training robust AI systems.
Generation Technique Analysis
In 2024, the Agent-based system segment held a dominant market position in the synthetic data generation market, capturing more than a 61.7% share. This substantial market share can be attributed to the segment’s capability to simulate complex behaviors and interactions within virtual environments, which are crucial for sectors such as urban planning, transportation, and healthcare.
Agent-based systems model the autonomous actions of agents – which can represent people, vehicles, or even cells – within a simulated environment, allowing for detailed analysis and prediction of dynamic systems. The superiority of agent-based systems in handling complexity and emergent phenomena makes them particularly valuable for applications requiring detailed scenario analysis and system behavior forecasting.
For example, in urban planning, these systems help in simulating pedestrian flows or traffic patterns, thereby assisting city planners in making informed decisions about infrastructure development and public safety measures. Similarly, in healthcare, they can model the spread of infectious diseases within various population segments under different intervention strategies, aiding in public health planning and response.
Moreover, the integration of agent-based models with other technologies like IoT and big data analytics has further expanded their applicability. This integration allows for real-time data to be fed into simulations, enhancing the accuracy and timeliness of the insights derived.
Such capabilities are invaluable for industries that operate in rapidly changing environments, such as financial markets or supply chain management, where being able to predict and adapt to changes can significantly influence success.
The ongoing advancements in computational power and algorithmic efficiency are expected to further bolster the growth of the agent-based system segment. As these models become more sophisticated and accessible, their adoption across a wider range of industries is likely to increase, maintaining their leading position in the synthetic data generation market.
Application Analysis
In 2024, the AI/ML model training segment held a dominant market position in the synthetic data generation market, capturing more than a 31.7% share. This leadership is largely due to the increasing reliance on artificial intelligence and machine learning across a broad spectrum of industries, ranging from automotive to healthcare, where the development of accurate and robust AI models is critical.
Synthetic data serves as a foundational element in training these models, especially in scenarios where real data is scarce, too sensitive, or costly to obtain. The appeal of synthetic data in AI/ML model training lies in its ability to provide large volumes of annotated training data at a fraction of the cost and time required to collect and label real-world data.
For instance, in the field of autonomous driving, synthetic data can simulate myriad driving conditions, vehicle interactions, and pedestrian behaviors that would be almost impossible to gather in sufficient quantities in the real world. This not only accelerates the training process but also enhances the AI models’ ability to generalize across different scenarios, thus improving their performance and reliability.
Moreover, synthetic data helps in overcoming significant challenges related to privacy and security, particularly in sectors like healthcare where data is subject to stringent regulatory protections. By using synthetic data that mimics real patient data without containing any actual patient information, developers can train predictive models for disease diagnosis and treatment recommendations while adhering to privacy laws such as HIPAA in the U.S.
The ongoing innovation in synthetic data generation technologies, especially advancements in deep learning methods that generate more realistic and complex datasets, continues to drive the adoption of synthetic data in AI/ML model training.
End Use Analysis
In 2024, the healthcare and life sciences segment held a dominant market position in the synthetic data generation market, capturing more than a 23.9% share. This leadership is largely driven by the critical need for vast amounts of diverse data to develop and validate medical diagnostics, treatment protocols, and personalized medicine approaches.
Synthetic data plays an essential role here, as it enables researchers and healthcare providers to simulate various patient demographics and disease scenarios without compromising patient privacy. The growing emphasis on precision medicine and the expansion of genetic research are key factors propelling the demand for synthetic data in this sector.
As these fields require specific data on rare conditions that are often not available in sufficient quantities, synthetic data provides a viable solution by allowing the generation of detailed, accurate datasets that can be used for research without ethical or legal repercussions.
Additionally, synthetic data facilitates the training and testing of AI-driven tools, such as predictive algorithms for disease onset, which are becoming increasingly integral to advancing healthcare outcomes. Privacy concerns also play a significant role in the adoption of synthetic data within healthcare and life sciences.
With stringent regulations such as GDPR in Europe and HIPAA in the United States, healthcare providers and researchers must navigate the complexities of data usage and patient confidentiality. Synthetic data offers a pathway to leverage critical data while adhering to these regulations, thereby supporting innovative research and clinical applications without risking privacy breaches.
Report Segmentation
By Data Type
- Image & video
- Tabular
- Text
- Others
By Offering
- Fully synthetic
- Partially synthetic
By Generation Technique
- Statistical methods & models
- Rule-based system
- Agent-based system
- Deep learning methods
- Others
By Application
- AI/ML model training
- Privacy protection
- Test data management
- Data analytics and visualization
- Others
By End Use
- BFSI
- Healthcare & life sciences
- Manufacturing
- Technology & telecommunications
- Automotive & transportation
- Others
Driver
Rising Demand for Data Privacy and Anonymization
One significant driver propelling the synthetic data generation market is the escalating demand for data privacy and anonymization solutions. As digital transformation deepens across industries, the imperative to protect sensitive consumer and business data while still harnessing it for strategic insights becomes crucial.
Synthetic data generation addresses this by creating datasets that maintain the utility of real data for analytics and machine learning without compromising individual privacy. This technology is particularly vital in sectors like healthcare and finance, where privacy concerns are paramount.
The growth of regulations such as GDPR in Europe and similar laws worldwide has further intensified the need for compliant data solutions, making synthetic data an attractive alternative to real data sets.
Restraint
Challenges in Maintaining Data Fidelity
A primary restraint in the synthetic data generation market is the challenge associated with maintaining the fidelity and quality of synthetic data. While synthetic data offers significant advantages in terms of privacy and compliance, ensuring that it accurately reflects the complex patterns, distributions, and anomalies present in real-world data is not always straightforward.
The risk is that synthetic data might not always capture outlier behaviors or rare events, which can be crucial for certain analyses and decision-making processes. Moreover, there are ongoing concerns about the potential for data leakage if the synthetic data generation algorithms inadvertently replicate unique identifiers or rare patterns from the original data.
Opportunity
Expansion into AI and Machine Learning
The market for synthetic data is also witnessing expansive opportunities in artificial intelligence (AI) and machine learning (ML) applications. As AI and ML technologies proliferate across various sectors, the need for large volumes of diverse, high-quality training data escalates.
Synthetic data enables the generation of vast datasets required for training complex models, particularly in scenarios where real data is scarce, too sensitive, or biased. This capability is crucial for advancing AI in areas such as autonomous driving, predictive maintenance, and personalized medicine, where real-world data can be limited or privacy-sensitive.
The ability to rapidly produce and utilize synthetic data to feed AI algorithms offers a significant growth pathway for this technology, enhancing model accuracy and functionality in a controlled, ethical manner.
Challenge
Technological Complexity and Integration Issues
A significant challenge in the synthetic data generation market is the technological complexity associated with developing and integrating synthetic data solutions. The process requires sophisticated understanding of both the domain of application and the nuances of data science, including knowledge of statistical distributions, data modeling, and algorithm design.
Organizations must also integrate these synthetic data solutions into existing IT environments and workflows, which can be complex and costly. The need for specialized skills to develop and manage synthetic data can pose a barrier to adoption, particularly for smaller organizations without the requisite technical expertise or resources.
Growth Factors
The synthetic data generation market is experiencing robust growth, driven by several key factors. Firstly, the increasing emphasis on data privacy and the need for compliance with data protection regulations such as GDPR are pushing companies towards synthetic data as a secure alternative to real data.
This trend is particularly pronounced in industries where data sensitivity is paramount, such as healthcare and finance. Another significant growth driver is the accelerating digital transformation across various sectors.
As businesses seek to harness the power of AI and machine learning, the demand for extensive datasets for training and validation purposes is skyrocketing. Synthetic data fills this gap effectively by providing high-quality, diverse, and scalable datasets that enhance the development and deployment of AI models without compromising on privacy or security.
The study by Synthesis AI and Vanson Bourne underscores the strategic importance of synthetic data among technology decision-makers, with 89% acknowledging its critical role in their organizational strategies. This indicates a strong consensus on the value of synthetic data in enhancing machine learning models, improving AI accuracy, and ensuring robust data privacy measures
Moreover, the expansion of IoT and connected device technologies further amplifies the need for synthetic data. These technologies require vast amounts of data to optimize and ensure reliability, and synthetic data offers a way to generate this data efficiently and safely, supporting rapid innovation and deployment in smart technology environments.
Emerging Trends
Emerging trends in the synthetic data generation market are reshaping its landscape. One notable trend is the integration of advanced AI techniques such as deep learning and generative adversarial networks (GANs) to create more realistic and complex datasets.
These technologies enable the generation of synthetic data that is nearly indistinguishable from real data, providing better training materials for AI and machine learning models without the risk of exposing sensitive information.
Another trend is the move towards cloud-based synthetic data generation solutions, which offer scalability and accessibility to companies of all sizes. This shift is particularly advantageous for small and medium-sized enterprises that may not have the resources to invest heavily in on-premise solutions but still need to leverage synthetic data for their AI initiatives.
The use of synthetic data to enhance the fairness and inclusivity of AI models is also gaining traction. By creating diverse and balanced datasets, companies can train AI systems that are free from biases present in real-world data, thereby making AI applications more equitable and effective across different demographics and scenarios.
Business Benefits
The business benefits of synthetic data generation are substantial and multifaceted. Firstly, it significantly enhances data privacy and security, enabling companies to utilize and share data without risking breaches of sensitive information. This aspect is crucial for maintaining customer trust and compliance with strict data protection laws.
Synthetic data also reduces the cost and time associated with data collection and labeling. By generating synthetic datasets on-demand, companies can bypass the often resource-intensive processes of gathering and annotating real-world data, thereby accelerating the pace of research and development.
Furthermore, synthetic data allows for the testing and validation of systems under a variety of conditions that may be rare or difficult to capture in the real world. This capability is particularly valuable in fields like autonomous driving and healthcare, where safety and accuracy are critical, and real-world testing can be prohibitively expensive or unethical.
Key Regions and Countries
- North America
- US
- Canada
- Europe
- Germany
- France
- The UK
- Spain
- Italy
- Rest of Europe
- Asia Pacific
- China
- Japan
- South Korea
- India
- Australia
- Singapore
- Rest of Asia Pacific
- Latin America
- Brazil
- Mexico
- Rest of Latin America
- Middle East & Africa
- South Africa
- Saudi Arabia
- UAE
- Rest of MEA
Key Player Analysis
The synthetic data generation market is witnessing significant activity among its key players, particularly in areas of acquisitions, product launches, and strategic collaborations. Three major companies at the forefront of these developments are Microsoft, Databricks, and Synthesis AI.
In January 2023, Microsoft amplified its AI initiatives through a multi-billion-dollar partnership with OpenAI. This alliance is primarily focused on democratizing AI technologies, making advanced AI tools more accessible to a wider audience. The collaboration has already led to the development of influential technologies like GPT-3.
Databricks expanded its capabilities in data governance through the acquisition of Okera in May 2023. This acquisition is strategic as it enhances Databricks’ offerings, allowing integration of more comprehensive data governance tools that are pivotal for AI applications.
In May 2023, Synthesis AI launched a new enterprise synthetic dataset on the Snowflake marketplace. This launch is significant as it provides customers with easy access to high-quality synthetic datasets, particularly synthetic human faces, which are crucial for developing advanced computer vision models without compromising consumer privacy.
Top Key Players in the Market
- Synthesis AI
- Statice
- Mostly AI
- YData
- Ekobit d.o.o.
- Hazy
- Kinetic Vision, Inc.
- Kymera-labs
- MDClone
- Neuromation
- TwentyBN
- DataGen Technologies
- Informatica Test Data Management
Recent Developments
- MOSTLY AI’s Open-Source Toolkit (February 2025): MOSTLY AI unveiled an open-source synthetic data generation toolkit, enabling organizations to generate high-quality synthetic data.
- In October 2024, Mostly AI introduced an advanced synthetic text tool designed to help organizations navigate the limitations of public datasets when training LLMs. This innovation enables businesses to leverage their proprietary text data – including emails, chatbot interactions, and customer support transcripts – while ensuring compliance with stringent privacy regulations.
Report Scope
| Report Features | Description |
|---|---|
| Market Value (2024) | USD 313.5 Mn |
| Forecast Revenue (2034) | USD 6,637.9 Mn |
| CAGR (2025-2034) | 35.7% |
| Base Year for Estimation | 2024 |
| Historic Period | 2020-2023 |
| Forecast Period | 2025-2034 |
| Report Coverage | Revenue forecast, AI impact on market trends, Share Insights, Company ranking, competitive landscape, Recent Developments, Market Dynamics and Emerging Trends |
| Segments Covered | By Data Type (Image & video, Tabular, Text, Others), By Offering (Fully synthetic, Partially synthetic), By Generation Technique (Statistical methods & models, Rule-based system, Agent-based system, Deep learning methods, Others), By Application (AI/ML model training, Privacy protection, Test data management, Data analytics and visualization, Others), By End Use (BFSI, Healthcare & life sciences, Manufacturing, Technology & telecommunications, Automotive and transportation, Others) |
| Regional Analysis | North America – US, Canada; Europe – Germany, France, The UK, Spain, Italy, Russia, Netherlands, Rest of Europe; Asia Pacific – China, Japan, South Korea, India, New Zealand, Singapore, Thailand, Vietnam, Rest of APAC; Latin America – Brazil, Mexico, Rest of Latin America; Middle East & Africa – South Africa, Saudi Arabia, UAE, Rest of MEA |
| Competitive Landscape | Synthesis AI, Statice, Mostly AI, YData, Ekobit d.o.o., Hazy, Kinetic Vision, Inc., Kymera-labs, MDClone, Neuromation, TwentyBN, DataGen Technologies, Informatica Test Data Management |
| Customization Scope | Customization for segments, region/country-level will be provided. Moreover, additional customization can be done based on the requirements. |
| Purchase Options | We have three license to opt for: Single User License, Multi-User License (Up to 5 Users), Corporate Use License (Unlimited User and Printable PDF) |





