
Global Synthetic Data For Banking Market Size, Share and Analysis Report By Component (Software, Services), By Data Type (Tabular Data, Time Series Data, Text Data, Image & Video Data, Others), By Application (Fraud Detection, Risk Management, Customer Analytics, Credit Scoring, Marketing Analytics, Compliance & Regulatory Reporting, Model Training & Testing, Others), By Deployment Mode (On-Premises, Cloud), By End-User (Retail Banking, Corporate Banking, Investment Banking, Credit Unions & Smaller Financial Institutions, Fintech Companies, Others) , By Regional Analysis, Global Trends and Opportunity, Future Outlook By 2025-2034
- Published date: Dec. 2025
- Report ID: 172112
- Number of Pages: 382
- Format:
-
keyboard_arrow_up
Quick Navigation
- Report Overview
- Key Takeaway
- Quick Market Facts
- Role of Generative AI
- U.S. Market Size
- Increasing Adoption Technologies
- Component Analysis
- Data Type Analysis
- Application Analysis
- Deployment Mode Analysis
- End-User Analysis
- Emerging Trends
- Growth Factors
- Driver Analysis
- Restraint Analysis
- Opportunity Analysis
- Challenge Analysis
- Key Market Segments
- Key Players Analysis
- Industry-Specific Use Cases
- Recent Developments
- Report Scope
Report Overview
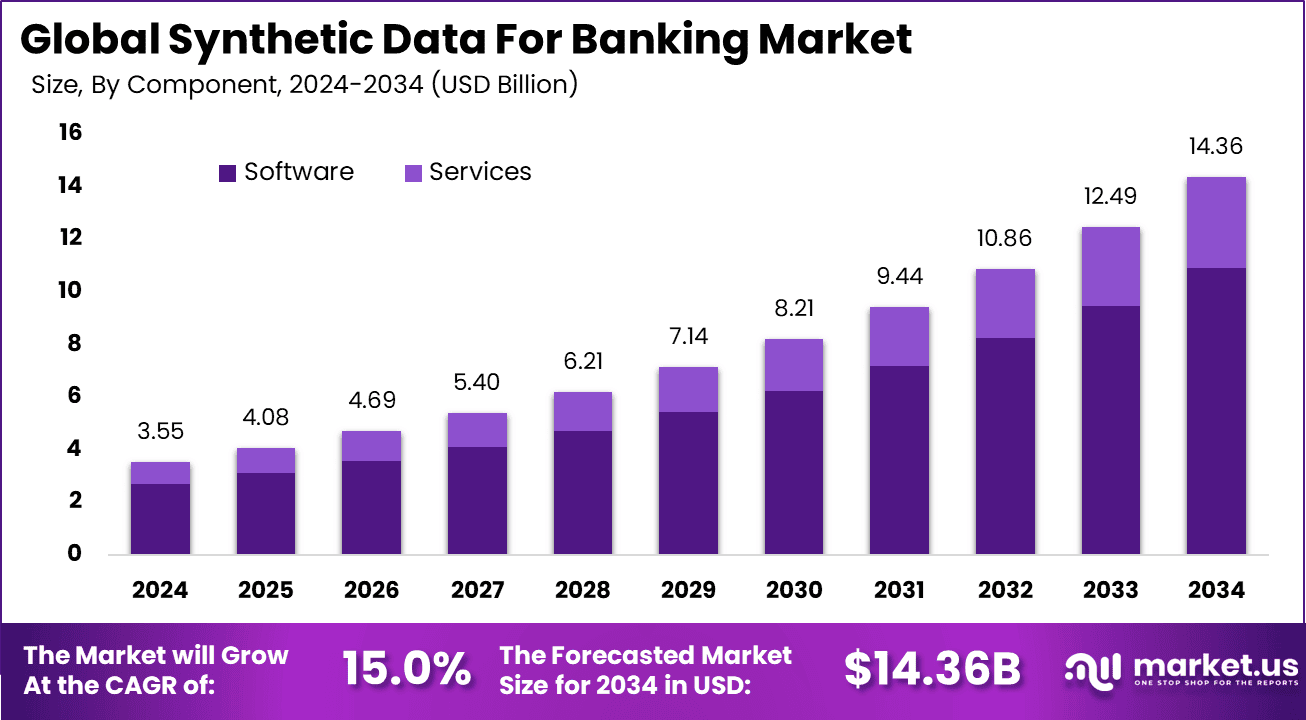
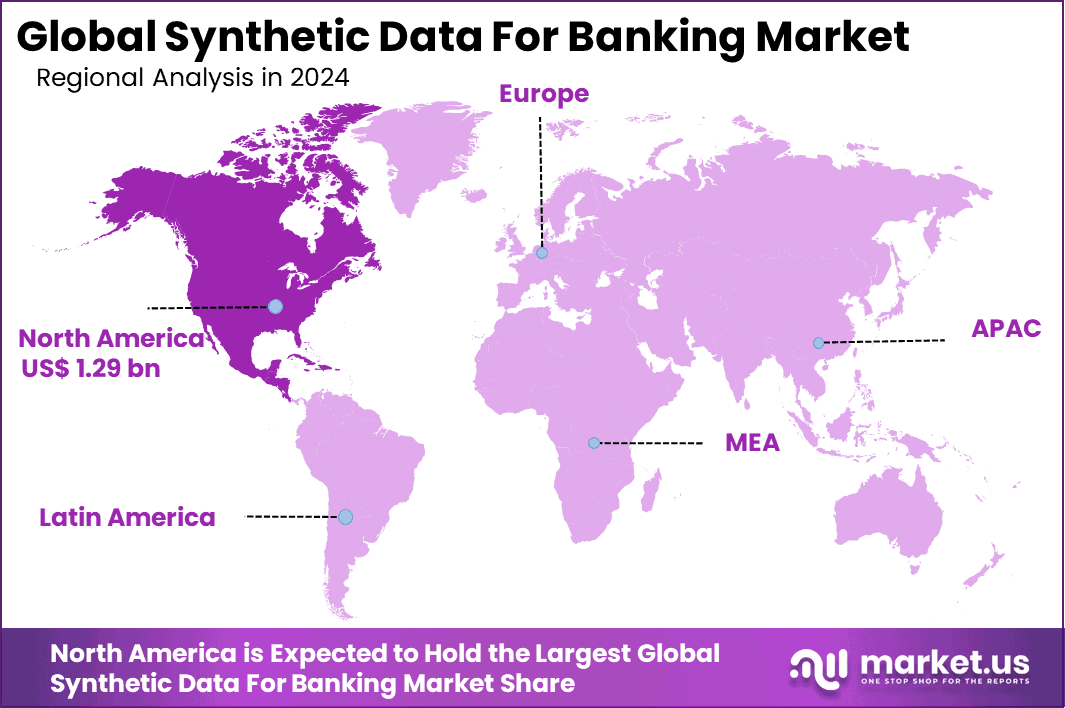
The Global Synthetic Data for Banking Market size is expected to be worth around USD 14.36 billion by 2034, from USD 3.55 billion in 2024, growing at a CAGR of 15.0% during the forecast period from 2025 to 2034. North America held a dominant market position, capturing more than a 36.4% share, holding USD 1.29 billion in revenue.
The synthetic data for banking market refers to the use of artificially generated data that mimics real customer, transaction, and operational data in financial institutions. Synthetic data supports activities such as model training, software testing, risk analysis, and compliance assessments without exposing actual personal information. In banking, synthetic data helps address data privacy concerns while enabling data-driven innovation across analytics, machine learning, and process validation.
As banks adopt modern technologies such as artificial intelligence and automation, demand for representative data increases. Real customer data cannot always be used due to regulatory constraints on privacy and data protection. Synthetic data provides a controlled alternative, allowing banks to simulate diverse scenarios, test new products, and validate models without risking sensitive information. This balance of usability and privacy is central to market development.
For instance, in December 2025, JPMorgan Chase & Co. showcased synthetic data breakthroughs at Prod Con 2025, simulating rare events like market crashes for better AI training across its massive operations. With over 150,000 staff leveraging these models, it’s a clear sign of how American banks are turning synthetic data into a competitive edge for resilient finance.
Key Takeaway
- In 2024, software solutions dominated the synthetic data for banking market with a 68% share, reflecting strong demand for platforms that generate, manage, and validate synthetic datasets for analytics and AI training.
- Tabular data led data type adoption with 60%, as structured banking data such as transactions, customer records, and account histories remain central to model development and testing.
- Fraud detection accounted for 65% of application usage, highlighting the role of synthetic data in training and validating models without exposing sensitive customer information.
- On-premises deployment captured 24%, indicating continued preference among banks for local control in highly regulated environments.
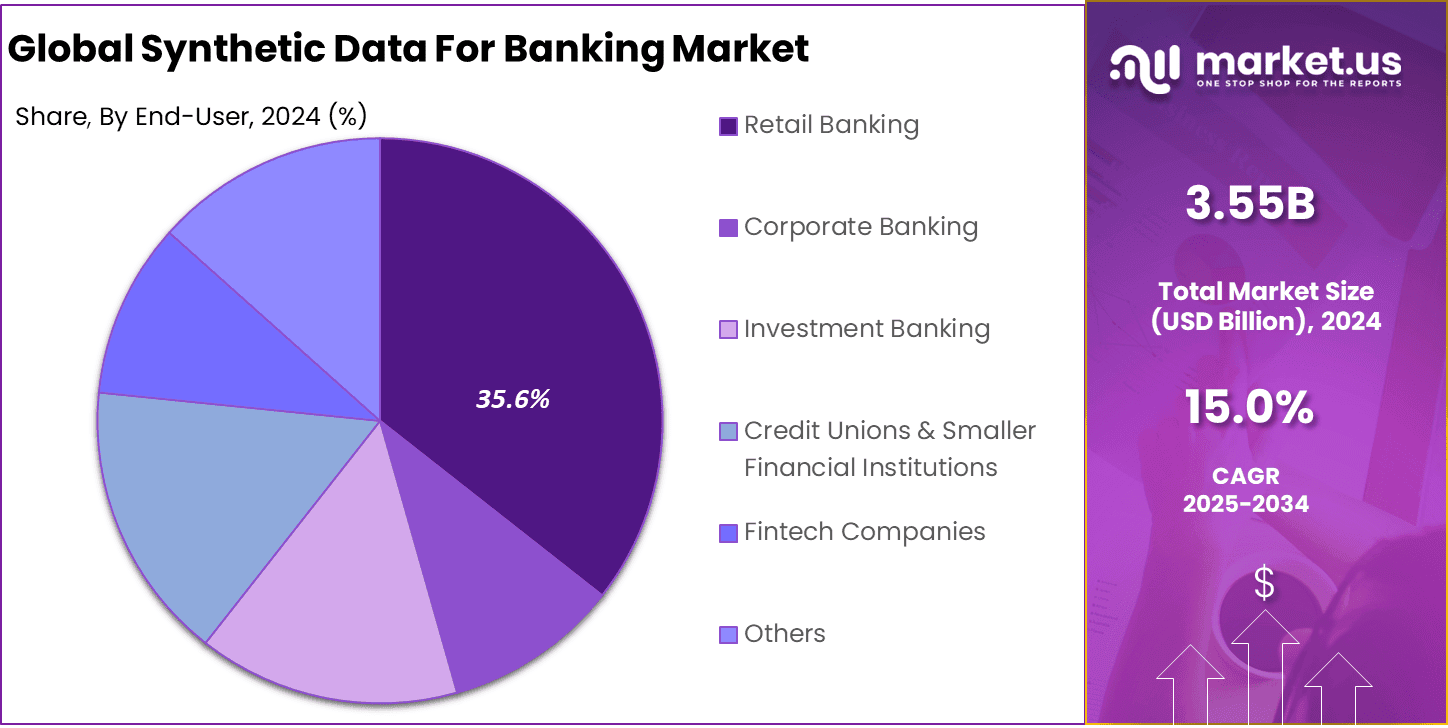
- Retail banking represented 35.6% of end-use demand, driven by large transaction volumes and increasing use of AI for risk and customer analytics.
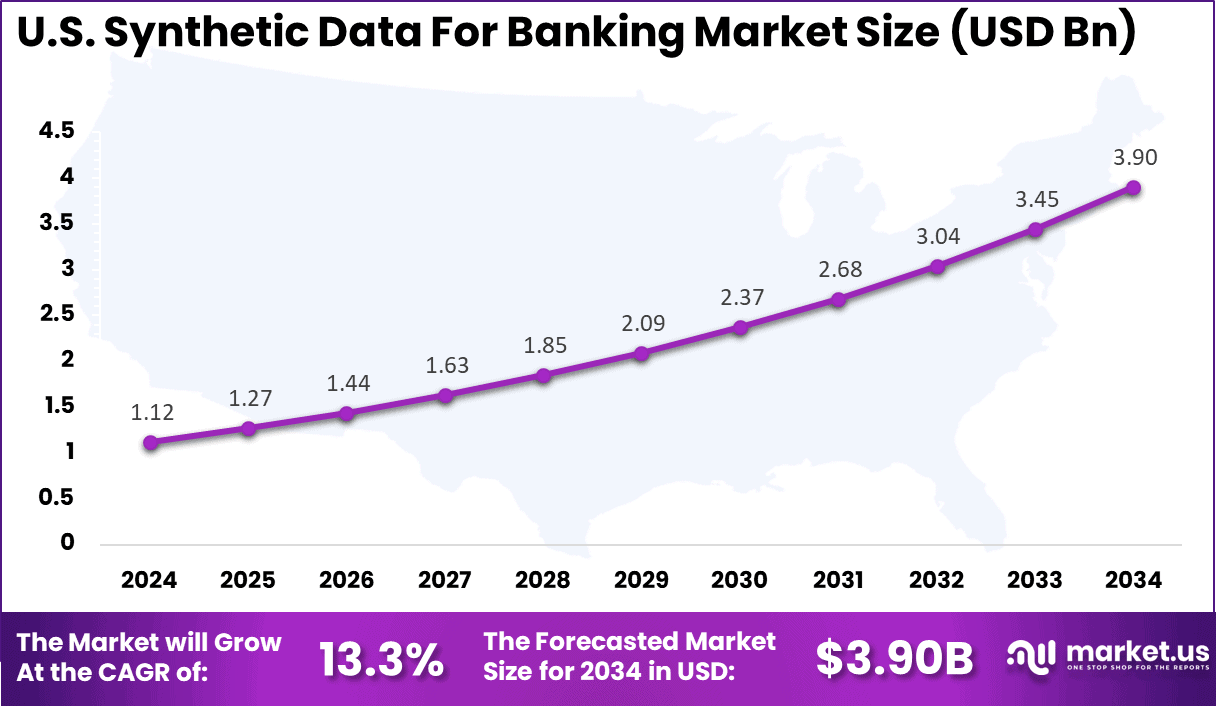
- The U.S. market reached USD 1.12 billion in 2024 and is expanding at a 13.3% CAGR, supported by rising AI adoption and data privacy requirements.
- North America led globally with over 36.4% share, backed by advanced banking technology adoption and strict regulatory focus on data security.
Quick Market Facts
Adoption and Usage Statistics
- AI adoption is a key growth driver in banking, with 91% of financial services firms assessing or using AI in production, according to a 2024 survey by NVIDIA.
- Synthetic data plays a central role in this shift, as 46% of banks already use it for AI training and development.
- In fraud detection, synthetic transaction data delivers 96-99% utility equivalence to production data for testing AML models.
- AI fraud systems trained on synthetic data have achieved detection accuracy of up to 99.18% in selected use cases.
- Early adopters report 40-60% faster proof-of-concept cycles, as synthetic data removes delays linked to anonymization and approvals.
- By 2025, around 75% of large banks are expected to rely on synthetic data to support multiple AI-driven initiatives.
Key Usage Areas in Banking
- Fraud Detection and Risk Management: Synthetic data enables generation of rare and complex fraud scenarios without exposing sensitive customer information.
- Model Training and Testing: Banks use large, high-quality synthetic datasets to train AI and ML models for credit scoring, customer analytics, and transaction monitoring.
- Test Data Management: Realistic synthetic datasets support software testing and cloud migration while minimizing data breach risks.
- Data Sharing: Synthetic data allows secure collaboration with third-party vendors and partners without violating privacy regulations such as GDPR.
- Bias Mitigation: Banks apply synthetic data to rebalance datasets by oversampling underrepresented groups, supporting fairer and more ethical AI models.
Role of Generative AI
Generative AI plays a central role in synthetic data for banking by using models like GANs and VAEs to produce realistic datasets that match real-world distributions. These models learn patterns from limited real data and generate unlimited synthetic samples for machine learning training in fraud detection and credit scoring. Banks benefit from this approach as it ensures privacy compliance while maintaining data utility for AI development.
This technology enhances scenario testing by simulating rare events like market crashes or transaction anomalies that real data rarely captures. Generative AI refines synthetic data quality through iterative training, reducing biases and improving model accuracy in risk management applications. Financial institutions integrate it into pipelines for continuous data generation, accelerating innovation in personalized banking services.
Generative AI refines synthetic data quality through iterative training, reducing biases and improving model accuracy in risk management applications, where frameworks achieve 94% downstream model performance retention in fraud detection. Financial institutions integrate it into pipelines for continuous data generation, accelerating innovation in personalized banking services amid 52% adoption of generative AI in financial services in 2024.
U.S. Market Size
The market for Synthetic Data for Banking within the U.S. is growing tremendously and is currently valued at USD 1.12 billion, the market has a projected CAGR of 13.3%. The market is growing due to strict privacy regulations like CCPA that limit real data use, rising fraud threats demanding better AI training, and data shortages in retail operations.
Banks turn to synthetic tools for safe testing of fraud detection and customer analytics. On-premises software generates tabular data quickly, helping teams innovate without compliance risks. This shift boosts efficiency across segments.
For instance, in December 2023, DataCebo, Inc. continues leading with SDV Enterprise, generating production-like synthetic tabular data for banking fraud testing and ML training using GANs. This on-premises solution supports complex enterprise logics without sensitive info exposure, solidifying U.S. innovation in scalable synthetic data platforms for financial services.
In 2024, North America held a dominant market position in the Global Synthetic Data for Banking Market, capturing more than a 36.4% share, holding USD 1.29 billion in revenue. This dominance is due to advanced tech infrastructure that supports quick AI adoption, strict privacy laws like CCPA pushing banks away from real data, and high fraud rates needing robust detection tools.
For instance, in September 2025, Onix Networking Corp. promoted its Kingfisher synthetic data generator for BFSI AI agents in fraud detection and risk assessment. The tool creates compliant, petabyte-scale datasets mimicking real financial data, enabling safe model training amid privacy constraints. Onix’s framework positions North American firms at the forefront of operationalizing synthetic data for transformative banking AI.
Increasing Adoption Technologies
Banks adopt generative models and simulation-based tools to create synthetic data at scale for enterprise-wide use. Technologies like diffusion models and neural networks generate transaction histories and behavioral profiles indistinguishable from real data. Integration with existing data lakes allows seamless deployment for analytics teams and third-party vendors.
Cloud-based platforms enable rapid prototyping of synthetic datasets for stress testing and algorithmic trading. Privacy-enhancing techniques embedded in these tools ensure compliance during data sharing with partners. Adoption accelerates through user-friendly interfaces that empower non-technical staff to access decision-ready data without governance hurdles.
Privacy preservation ranks as a primary reason, allowing banks to train AI on representative data without risking PII exposure under GDPR or PCI DSS. Synthetic data overcomes real-data silos caused by compliance barriers, unlocking insights for revenue-generating decisions. It fills gaps in rare-event data, improving fraud detection and risk models beyond historical limitations.
Scalability drives adoption by producing unlimited volumes instantly, supporting AI expansion without collection costs. Banks gain faster time-to-market for products through accelerated testing and vendor collaborations. Bias mitigation in synthetic generation leads to equitable lending and servicing, enhancing trust and operational efficiency.
Component Analysis
In 2024, The Software segment held a dominant market position, capturing a 75.9% share of the Global Synthetic Data for Banking Market. Banks turn to these tools because they create realistic datasets that mimic real customer behaviors without exposing sensitive information. This approach lets teams train AI models for tasks like risk assessment and customer service improvements.
Daily operations run smoothly as software handles complex data generation quickly and reliably. It fits right into existing workflows, making it a go-to choice for most institutions. The rise of software solutions stems from the need for scalable data in regulated environments.
Banks face constant pressure to innovate while staying compliant, and these tools deliver just that. They generate varied scenarios for testing, from transaction patterns to loan approvals. Teams appreciate how easy it is to integrate them with current systems. Over time, this segment keeps growing as banks push for more advanced analytics without real data risks.
For Instance, in June 2025, JPMorgan Chase filed a patent for software that generates fair synthetic data from real collections. It ensures models avoid bias in areas like loan approvals by matching demographics evenly. The bank uses this to train machine learning safely across components. Teams see it as a step toward equitable AI in banking.
Data Type Analysis
In 2024, the Tabular Data segment held a dominant market position, capturing a 39.7% share of the Global Synthetic Data for Banking Market. It shines for structured records like account details or payment histories that banks manage in tables.
Privacy concerns make real data hard to use, so synthetic versions fill the gap perfectly. Analysts use it for quick reports and forecasts, keeping operations efficient. This format matches everyday banking needs, from spreadsheets to database queries.
Banks prefer tabular data because it processes fast and integrates seamlessly with tools like Excel or SQL. It supports core functions such as compliance checks and performance tracking. Generating this data avoids the hassles of anonymization, saving time and effort. As volumes grow, synthetic tabular sets help teams spot trends without privacy worries. This steady demand reflects its practical value in daily banking tasks.
For instance, in August 2025, Onix Networking released an eBook on using synthetic tabular data in BFSI with their Kingfisher tool. It tackles data scarcity by mimicking real tables for AI training. Financial firms apply it to transaction records and customer profiles. This fits perfectly for everyday tabular needs.
Application Analysis
In 2024, The Fraud Detection segment held a dominant market position, capturing a 32.5% share of the Global Synthetic Data for Banking Market. Banks deal with clever scams daily, and synthetic data recreates rare fraud events for better training. Detection models improve, reducing false positives that frustrate customers. Teams test strategies safely, honing skills on simulated attacks. This keeps security tight without risking real accounts.
The focus on fraud grows with rising threats in digital banking. Synthetic data lets banks build robust systems by practicing on endless scenarios. It cuts development time and boosts accuracy in spotting issues early. Analysts value how it mirrors real patterns closely. Overall, this application drives adoption as banks prioritize protection in a threat-filled landscape.
For Instance, in October 2025, IBM launched synthetic datasets targeting fraud in instant payments for financial institutions. The tools simulate real fraud cases to train models efficiently. A partner reported fewer false alerts after using it. Banks integrate this into core fraud systems for better accuracy.
Deployment Mode Analysis
In 2024, The On-Premises segment held a dominant market position, capturing a 74.8% share of the Global Synthetic Data For Banking Market. Banks choose it for full control over data, especially with strict security rules in place. Keeping everything in-house avoids cloud vulnerabilities and meets compliance needs head-on. Teams access tools instantly without internet dependencies. This setup suits large institutions handling massive sensitive volumes.
Security remains the top reason for on-premises preference in banking. It allows custom configurations tailored to internal policies. Maintenance stays predictable, with IT teams overseeing updates. As data privacy laws tighten, this mode offers peace of mind. Banks stick with it for reliable performance in critical operations like model training and audits.
For Instance, in July 2025, Infosys shared insights on AI-enabled synthetic data for risk management in finance. Their on-premises approach generates tabular sets for local model training. Banks deploy it to handle sensitive data securely. This setup supports tight regulatory environments.
End-User Analysis
In 2024, The Retail Banking segment held a dominant market position, capturing a 35.6% share of the Global Synthetic Data for Banking Market. High customer volumes demand safe data for personalization and service tweaks. Branches use it to profile behaviors and predict needs without privacy breaches. Every day tasks like transaction analysis benefit greatly. This segment leads as retail faces the most data demands daily.
Retail banks thrive on customer insights, and synthetic data delivers them cleanly. It powers marketing campaigns and supports improvements effectively. Teams experiment freely, refining approaches based on realistic simulations. With millions of accounts to manage, this tool scales effortlessly. Its dominance highlights retail’s push for data-driven decisions in competitive markets.
For Instance, in September 2025, Syntheticus promoted synthetic data solutions tailored for retail banking challenges. It generates datasets for customer analytics and risk prediction without real data. Retail banks use it to personalize services safely. This drives better decision-making daily.
Emerging Trends
Shift Toward Privacy-Preserving Model Development
A key trend in the synthetic data for banking market is the focus on privacy-preserving development of predictive models. Banks use synthetic datasets to train and validate credit scoring, fraud detection, and customer segmentation models without accessing identifiable data. Synthetic data reduces the risk of exposing personal information while supporting robust model performance testing across varied conditions.
Another emerging trend is integration of synthetic data with cloud platforms and analytics pipelines. As financial institutions move data processing and analytics workloads to cloud environments, synthetic data can be generated and stored within secure cloud systems. This approach improves scalability and allows banks to combine synthetic data with sandbox environments for experimentation without affecting production systems.
Growth Factors
Increase in Data-Driven Initiatives and Regulatory Pressure
A major growth factor for this market is the expansion of data-driven initiatives within banks. Financial institutions use analytics and machine learning for credit risk assessment, customer behavior analysis, and operational efficiency improvements. These activities require large volumes of quality data. Synthetic data helps fill gaps where real data is restricted or unavailable due to privacy concerns.
Another growth factor is regulatory pressure related to data protection. Privacy laws such as GDPR, CCPA, and sector-specific mandates restrict how banks use customer data for testing and analytics. Synthetic data addresses compliance by providing datasets that preserve statistical properties of real data without exposing actual identifiers. This compliance support increases adoption within risk and compliance functions.
Driver Analysis
Need for Risk Mitigation and Model Validation
A key driver of the synthetic data for banking market is the need for risk mitigation in analytics and model deployment. Banks must ensure that predictive models perform reliably under varied scenarios and data conditions. Using synthetic data allows organizations to test models against edge cases and rare events that may not be present in historical records. This wider test coverage strengthens model validation processes.
Another driver is the growing complexity of banking ecosystems. Modern banking systems integrate multiple data sources such as transaction logs, customer interactions, and market feeds. Using actual data for experimentation carries risk of misuse or leakage. Synthetic data enables experimentation without exposing sensitive underlying records. This improves operational agility and supports innovation in controlled environments.
For instance, in October 2025, Spar Nord Bank used DataCebo’s tools to create synthetic data for anti-money laundering checks. This kept real customer details safe during model training. Teams tested systems without privacy risks. Workflows sped up as data became available on demand. Compliance stayed solid across the board.
Restraint Analysis
Quality Concerns and Technical Complexity
A significant restraint in this market is maintaining the quality and utility of synthetic data. If synthetic data does not accurately reflect the structure and relationships of real data, models trained or validated on it may perform poorly in production. Ensuring high-fidelity synthetic data requires advanced generation techniques and rigorous testing, which increases complexity.
Another restraint arises from technical complexity in generating synthetic datasets. Banks may require specialized tools, domain expertise, and integration with existing data infrastructure. Smaller institutions with limited technical resources may delay adoption until simpler or more accessible solutions become available.
Opportunity Analysis
Expansion of Use Cases and Cross-Functional Adoption
There is strong opportunity in expanding the use of synthetic data beyond analytics teams. Functions such as software testing, user experience evaluation, and system integration tests benefit from synthetic datasets that simulate real usage patterns. Banks that integrate synthetic data across IT, risk, and operations can improve overall development quality and reduce dependency on sensitive production data.
Another opportunity lies in the development of standardized synthetic data frameworks and platforms tailored to banking needs. Providers that offer domain-specific templates, compliance support, and integration with core banking systems can attract broader adoption. Standardization helps reduce implementation effort and increases confidence in synthetic data quality.
Challenge Analysis
Regulatory Interpretation and Data Governance
A major challenge in this market is navigating regulatory interpretation of synthetic data use. While synthetic data is designed to avoid exposing personal information, regulators may still require clear documentation and governance to confirm compliance. Banks must establish policies that demonstrate how synthetic data is generated, used, and protected, which adds administrative effort.
Another challenge involves data governance alignment. Synthetic data must be managed within existing governance frameworks that control data lineage, access rights, and quality standards. Ensuring that synthetic datasets align with organizational data policies requires careful planning and coordination between data teams, compliance officers, and business stakeholders. Managing this governance complexity can slow implementation.
For instance, in September 2025, Tech Mahindra partnered on AI anti-money laundering solutions. Synthetic data raised questions on regulatory fit. Validation processes extended timelines. Clear rules were missing for full rollout. Banks proceeded step by step amid uncertainty.
Key Market Segments
By Component
- Software
- Synthetic data generation platforms
- Tools for data modeling, validation, and augmentation
- AI/ML-based engines (e.g., GANs, deep learning)
- Privacy & fidelity management modules
- Others
- Services
- Professional services
- Integration & Deployment
- Custom Data Generation
- Support & Maintenance
- Managed Services
- Professional services
By Data Type
- Tabular Data
- Time Series Data
- Text Data
- Image & Video Data
- Others
By Application
- Fraud Detection
- Risk Management
- Customer Analytics
- Credit Scoring
- Marketing Analytics
- Compliance & Regulatory Reporting
- Model Training & Testing
- Others
By Deployment Mode
- On-Premises
- Cloud
By End-User
- Retail Banking
- Corporate Banking
- Investment Banking
- Credit Unions & Smaller Financial Institutions
- Fintech Companies
- Others
Regional Analysis and Coverage
- North America
- US
- Canada
- Europe
- Germany
- France
- The UK
- Spain
- Italy
- Russia
- Netherlands
- Rest of Europe
- Asia Pacific
- China
- Japan
- South Korea
- India
- Australia
- Singapore
- Thailand
- Vietnam
- Rest of Latin America
- Latin America
- Brazil
- Mexico
- Rest of Latin America
- Middle East & Africa
- South Africa
- Saudi Arabia
- UAE
- Rest of MEA
Key Players Analysis
The vendor landscape is typically organized around two core capability groups. The first group focuses on enterprise-grade synthetic data generation for structured financial datasets, where privacy protection and statistical realism are positioned as primary requirements. Platforms such as MOSTLY AI and Gretel are positioned around creating privacy-safe synthetic datasets for analytics and model development, with strong emphasis on enterprise deployment needs.
JPMorgan Chase & Co., IBM Corporation, and Infosys Limited play a key role in the synthetic data for banking market by using synthetic datasets to support risk modeling, fraud detection, and regulatory testing. Their initiatives help banks train AI models without exposing sensitive customer information. These organizations focus on data privacy, regulatory compliance, and scalable analytics. Rising pressure to protect personal data continues to accelerate adoption.
Syntheticus, NayaOne, DataCebo, and Syntho strengthen the market with purpose built synthetic data platforms for financial services. Their solutions generate statistically accurate datasets for testing, model validation, and innovation sandboxes. These providers emphasize data realism, bias control, and fast deployment. Growing use of AI and open banking frameworks supports wider demand.
Tech Mahindra Limited, Onix Networking Corp., and other players expand the landscape with integration services and cloud based synthetic data workflows. Their offerings help banks embed synthetic data into existing analytics and development pipelines. These companies focus on customization, security, and operational efficiency. Increasing regulatory scrutiny and AI adoption continue to drive steady growth in synthetic data usage across the banking sector.
Top Key Players in the Market
- JPMorgan Chase & Co.
- Syntheticus
- International Business Machines Corporation
- NayaOne
- Onix Networking Corp.
- DataCebo, Inc.
- Syntho
- Infosys Limited
- Tech Mahindra Limited
- Others
Industry-Specific Use Cases
Within fraud and financial crime controls, synthetic data is being applied to improve model development where real fraud examples are limited and highly sensitive. The FCA financial services report explicitly references use cases such as fraud detection, authorised push payment fraud, and anti-money laundering, showing that synthetic datasets are being considered to expand testing coverage and model validation without exposing customer identities.
In credit and customer decisioning, synthetic data is increasingly used for credit scoring development and broader analytics, especially when privacy restrictions limit access to granular customer information. The FCA report also lists credit scoring and open banking related use cases, indicating practical relevance for risk, onboarding, and data sharing scenarios.
In parallel, software delivery teams use synthetic datasets to support safer testing and quality assurance, so that feature releases and integration testing can proceed without copying production customer records into lower environments.
Recent Developments
- In September 2025, Onix Networking Corp. launched Kingfisher, a synthetic data generator tailored for BFSI fraud and risk AI. Handling petabyte-scale datasets that mirror live financial flows, it sidesteps privacy headaches while powering agentic models. Ohio-based innovation like this cements North America’s edge in practical AI deployment for banks.
- In October 2025, NayaOne teamed up with Valley Bank to supercharge fintech sandboxes with schema-driven synthetic data. Delivered in days, these production-mimicking sets slash compliance costs and speed up payment flow tests. It’s the kind of agile tooling that’s propelling North American fintechs past data roadblocks.
Report Scope
Report Features Description Market Value (2024) USD 3.5 Bn Forecast Revenue (2034) USD 14.3 Bn CAGR(2025-2034) 15% Base Year for Estimation 2024 Historic Period 2020-2023 Forecast Period 2025-2034 Report Coverage Revenue forecast, AI impact on Market trends, Share Insights, Company ranking, competitive landscape, Recent Developments, Market Dynamics and Emerging Trends Segments Covered By Component (Software, Services), By Data Type (Tabular Data, Time Series Data, Text Data, Image & Video Data, Others), By Application (Fraud Detection, Risk Management, Customer Analytics, Credit Scoring, Marketing Analytics, Compliance & Regulatory Reporting, Model Training & Testing, Others), By Deployment Mode (On-Premises, Cloud), By End-User (Retail Banking, Corporate Banking, Investment Banking, Credit Unions & Smaller Financial Institutions, Fintech Companies, Others) Regional Analysis North America – US, Canada; Europe – Germany, France, The UK, Spain, Italy, Russia, Netherlands, Rest of Europe; Asia Pacific – China, Japan, South Korea, India, New Zealand, Singapore, Thailand, Vietnam, Rest of Latin America; Latin America – Brazil, Mexico, Rest of Latin America; Middle East & Africa – South Africa, Saudi Arabia, UAE, Rest of MEA Competitive Landscape JPMorgan Chase & Co., Syntheticus, International Business Machines Corporation, NayaOne, Onix Networking Corp., DataCebo, Inc., Syntho, Infosys Limited, Tech Mahindra Limited, Others Customization Scope Customization for segments, region/country-level will be provided. Moreover, additional customization can be done based on the requirements. Purchase Options We have three license to opt for: Single User License, Multi-User License (Up to 5 Users), Corporate Use License (Unlimited User and Printable PDF)  Synthetic Data For Banking MarketPublished date: Dec. 2025add_shopping_cartBuy Now get_appDownload Sample
Synthetic Data For Banking MarketPublished date: Dec. 2025add_shopping_cartBuy Now get_appDownload Sample -
-
- JPMorgan Chase & Co.
- Syntheticus
- International Business Machines Corporation
- NayaOne
- Onix Networking Corp.
- DataCebo, Inc.
- Syntho
- Infosys Limited
- Tech Mahindra Limited
- Others
Our Clients
- 172112
- Dec. 2025




